Background
High availability is the degree to which an application, service, or function is accessible on demand. Users experience frustration when their data is unavailable or the computing system is not performing as expected. Users generally don’t differentiate between the complex components of an overall solution. Performance failures due to higher than expected usage create the same disruption as the failure of critical components and simply put, if a user cannot access the system, it is said to be ‘unavailable.’ If systems need to be ready to serve all users at all times, then high availability (HA) is the way to provide uninterrupted access.
Key Terms
There are few key terms used when discussing the implementation of high availability solutions.
- Tenant: A tenant is a dedicated environment for a company and its digital assets which contain users, domains, applications, and more. Each company has tenant administrators with the rights to configure settings for privileges and access to applications. A tenant domain is the company’s unique identifier for login, for example, https://login.<COMPANYNAME>.ztna.safous.com. You can have more than a single tenant in your Safous architecture and each tenant has its own login and separate DB. Each login is provided to different sets of end users and can contain different applications.
- Clusters: Generally speaking, a cluster is a group of computers (or nodes) that run in parallel, with work distributed among the nodes in the cluster. In Safous, a cluster is a tenant with at least 1 App Gateway and there can be more than 1 site in a cluster (A site in most cases is a geographical site in which the App Gateway has direct network access to its published resources). While one can install an odd or even number of App Gateways in a cluster, we recommend at least 3 App Gateways per cluster to achieve HA, as discussed more fully below.
- Voters vs Non-Voters: App Gateways in the cluster are considered voters but the number of voters in the cluster is determined at the time of implementation. For example, the first 3 App Gateways in the cluster are considered “voters” and App Gateways that join the cluster thereafter are considered non-voters.
- Leaders vs Followers: A leader is elected only by the voting App Gateways in the cluster. At any given time, a cluster has 1 App Gateway at a time that is ‘elected’ leader by the voting App Gateways. The task of “leader” switches constantly to a different voting App Gateways so that there are different leaders all the time. Only voter App Gateways can become leaders. Regardless of voters and non-voters, all those App Gateways that are not currently the leader are called followers
- Leader’s Responsibility for Data: There are 3 types of data in the Safous system:
-
Log Data: Where system logs are written
-
Application Data: Where applications, policies and identities are published
-
Main Data: All other data within the Safous platform
-
At any given moment there is a leader for every type of data. The leader is the node that writes the above data to the database, and synchronizes the same data to the rest of the cluster’s App Gateways who are not in the lead at the time.
Safous’s High Availability Solution
HA in Safous functions when there are at least 3 App Gateways in the cluster. The 3 App Gateways are voters and vote on the leader. The leading App Gateway is responsible for writing the data noted above to the database while also updating the other App Gateways. Every 90 seconds there is a new leader vote and the role of the leader changes such that any one of the 3 App Gateways in a cluster can become one. If the leader becomes unavailable, one of the followers is elected to take the leadership position which means you can keep your systems running even if one of the components in the system fails. All applications, policies, enrollment of users, and connections to the system will continue to run within that cluster. In order for a cluster to survive, an odd number of voting App Gateways need to be functioning.
Raft consensus algorithm is used to ensure that the App Gateways are synchronized at any given moment, which means that when a leader fails, either one of the two followers can be elected leaders since they are all replicates of each other. The state is replicated globally regardless of the site affinity of App Gateways. In HA situations, systems run smoothly because any of the voters are elected as leaders should the latter fail.
HA can also be achieved if there is a cluster with 2 sites, and each site, i.e., Site A and Site B, each have two App Gateways, for a total of 4 App Gateways in the cluster. If the designated leader in Site A falls, the other 3 App Gateways (the remaining one in Site A and the 2 in Site B) can elect the new leader, provided that the two sites are clustered. Please note that there will be no site redundancy in Site A, but you can still be in read/write mode. And if the lead App Gateway in Site A falls, and the App Gateways in Site B cannot reach Site A, then the applications in Site A will be inaccessible.
Equally important is that applications might be affiliated with one specific site and that site might only have 1 App Gateway. If that 1 App Gateway fails, service to the applications published on that App Gateway will fail because the application is served only by that 1 App Gateway.
If there are 2 App Gateways at 1 site, one App Gateway is a voter and the other is a non-voter. Should the non-voting App Gateway fail, the system continues to work but without HA.
Why is HA Important?
HA reduces interruptions and downtime. At times, emergencies will bring down even the most robust, reliable software and systems and HA systems minimize the impact of these events, and can often recover automatically from component or even server failures. When done properly deployed with 3 or more App Gateways, HA makes backups redundant by ensuring continuous operations and access to your systems, databases, and applications when and as needed. Unlike manual backups, HA structures orchestrate replicas in a distributed fashion so that users are never aware that that there was any systemic failure at all.
Disaster Recovery
Safous HA architecture offers you the ability to recover and restart from the point of a failure (resilience) and the ability to ensure that your applications are available for use in the event of system failure (performance). Because App Gateways share the same state, installing a new App Gateway from scratch as a replacement of a failed one will almost immediately keep the pace and start serving right away. The diagram below demonstrates HA deployment topography in a customer premises situation:
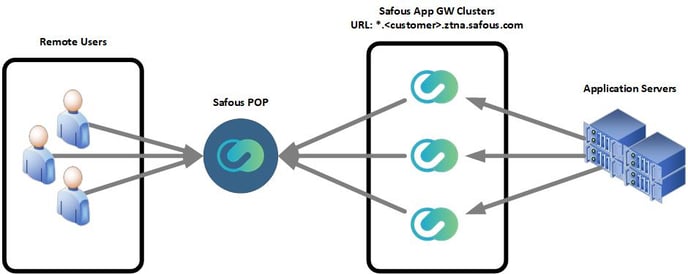
Downtime Without HA
Consider this scenario: Only 2 App Gateways are installed in a cluster and the leader node dies, first of all and most importantly, all data is kept on the remaining follower node, so there is no data loss. There is indeed a simple procedure to convert the remaining follower node to the leader but it should be conducted only by Safous support. Until the cluster will be fixed, when a cluster has no leader (i.e., when the leader becomes unavailable), the cluster enters a "read-only" mode and there can't be configuration changes until the cluster is able to elect a leader again. If an administrator tries to configure the cluster at this stage he will get the no leader error message:
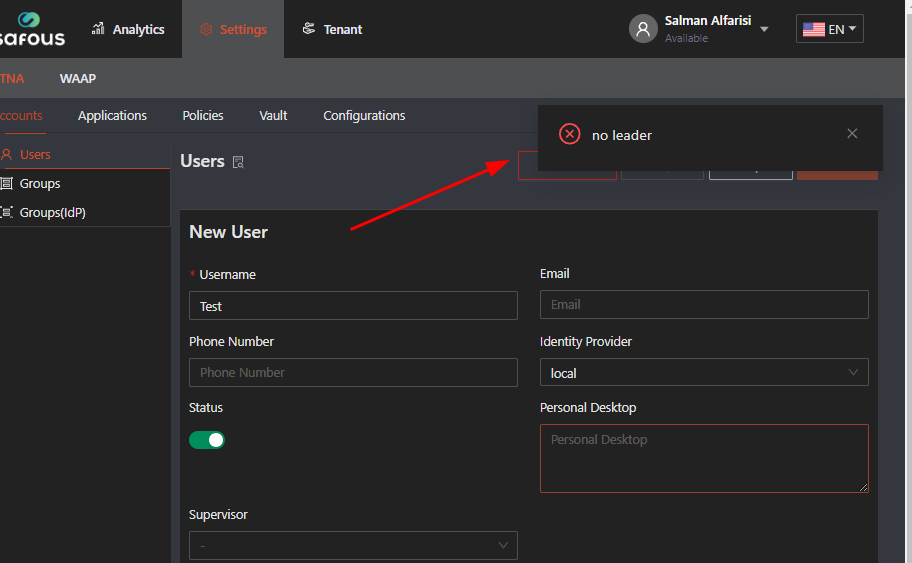
The logs will show:

For this reason we recommend installing a 3rd App Gateway in a cluster to achieve HA.
If the follower App Gateway crashes, the leader remains functioning so that if the two App Gateways are in the same site, the cluster will function as usual. But if these 2 App Gateways are in different sites, then the site that is covered by the fallen App Gateway will not have any applications accessible. A single server deployment is highly discouraged as data loss is inevitable in a failure scenario.
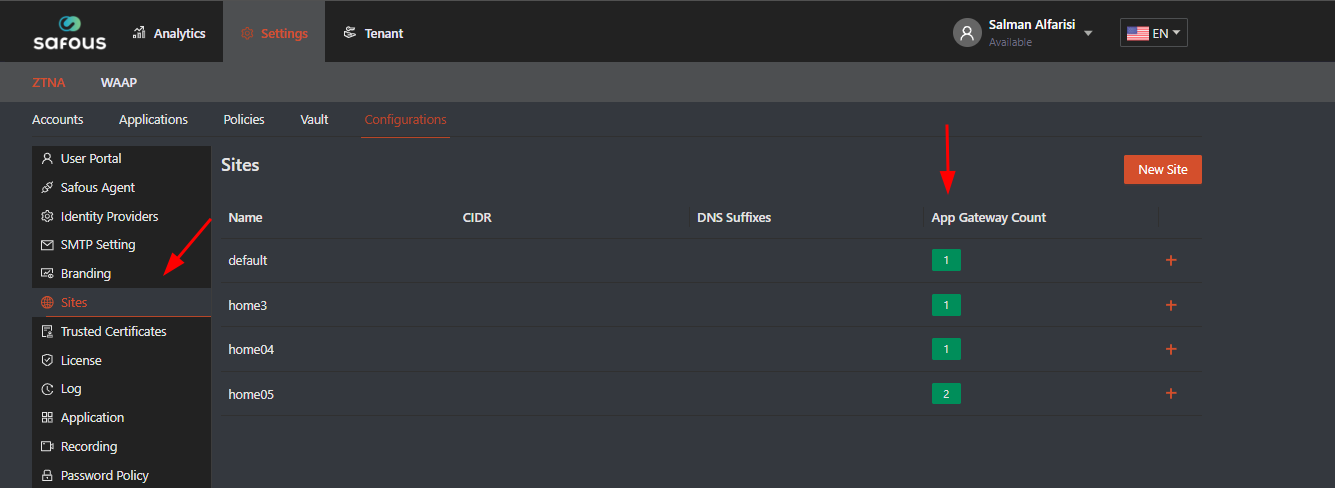
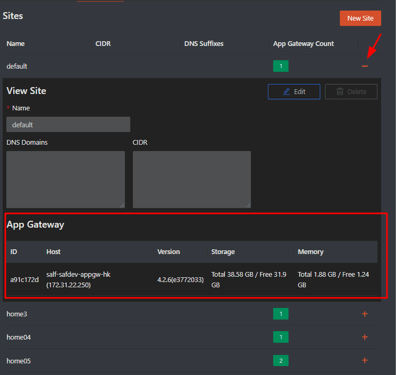
How To Deploy Safous HA
When you install your App Gateway, you specify the site it should represent as part of the installation process. Once the App Gateway is up and connected you will see its site name in the ZTNA Configuration page:
Safous HA Best Practices
In general, HA describes systems that are dependable enough to operate continuously without failing. Safous places great emphasis on both resilience and performance as core concepts of Safous HA architecture best practices. Together, resilience and performance recover and restart from the point of a failure (resilience) and the ability to ensure that your applications are available for use in the event of system failure (performance). Here are our recommendations for HA best practices:
-
App Gateway Health Checks: One of the most important things in App Gateways resilience and performance is ensuring that they are healthy in order to execute the HA scenario. The reason for this is simple: If an application is available only from a specific site, and if the site is left without any healthy App Gateways, the site won't be available, no matter how many App Gateways you have. Accordingly it is important to ensure App Gateway health.
-
Uptime: Health checks are important because they relate to uptime, which defines that system's reliability and percentage of time it is ready for use. Degradation in the amount of healthy App Gateways that serve a specific service won't cause a degradation in performance of that service except cases when all App Gateways within a specific site are down. In that case , only the services published explicitly from that site will become unavailable. Recovery of failed App Gateway will immediately affect the availability.
-
Load Balancing: App Gateways within the same site share the load equally to ensure maximum performance for the expected load. Services that are published globally, without an affinity to site, are routed through the shortest path from the user, geographically.
-
Data Availability: App Gateways form shared states using a consensus algorithm which requires a quorum (majority) of healthy nodes in order to provide resiliency to faulty nodes. This means that planning of deployment of the Safous product should consider the formula App Gateways / 2 + 1 as the minimum amount of App Gateways that are needed to perform changes to configurations and sessions. A good example of deployment scenario quorum in relation to the number of servers can be seen below:
|
Site Servers |
Quorum Size |
Failure Tolerance |
|
1 |
1 |
0 |
|
2 |
2 |
0 |
|
3 |
2 |
1 |
|
4 |
3 |
1 |
|
5 |
3 |
2 |
|
6 |
4 |
2 |
|
7 |
4 |
3 |
-
Disaster Recovery: Because the App Gateways share the same state, installing a new App Gateway from scratch, replacing a failed one, will almost immediately keep the pace and start serving your users.
HA Maintenance For Administrators
The best way to maintain HA is to monitor the App Gateways' health. There is no specific way to check whether HA is working within the Admin Portal at this time, but this feature will be released in the future. In the meantime, if an App Gateway needs to be restarted, manually connect to the server and restart the docker-compose.
Troubleshooting FAQs
Some of the most commonly occurring issues in HA situations relate to the App Gateways themselves and are listed below.
-
Resources consumption issues: Disk space, memory or CPU
-
Network issues: App Gateways reaching the cloud, sync issues between App Gateways in the cluster.
-
Upgrade issues: Migrations, like changing the database schema or failing to download docker images.